前言
訓練模型時候,總是期待如何讓訓練時間縮短,尤其是在做研究時候,往往會需要快速得到結果。後來發現AUTOMATIC MIXED PRECISION(AMP)套件能輕鬆提升訓練速度,在實際使用上準確度沒有明顯差別,但在訓練時間上節省滿多,因此在這邊紀錄。
淺談AMP原理
而在大部分深度學習套件預設都使用32位浮點( FP32 )進行訓練。後續NVIDIA研究人員研發一種混合精度訓練方式,將一部份運算運行在 FP32 ,而大部分都採用16位浮點( FP16 )進行運算。通過混和精度訓練好處除了能獲得接近 FP32 準確度,更能節省記憶體使用與訓練時間。
這邊就來比較一下FP32與FP16差異
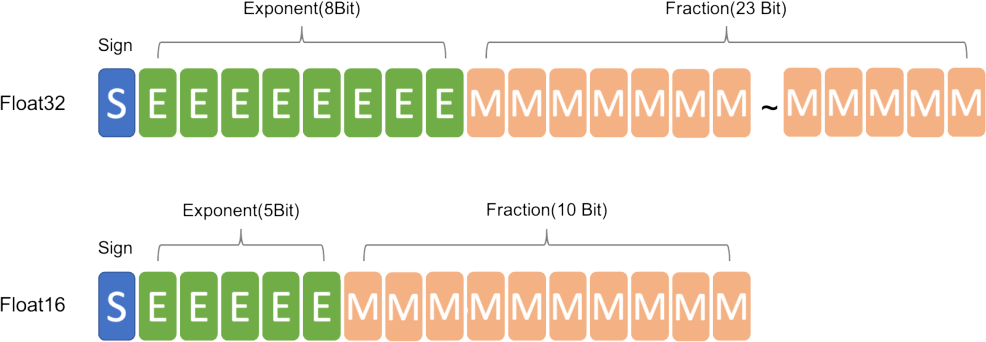
如果有學過計算機概論浮點數表示,在圖1能得知 FP32 能表示比起 FP16 數字範圍更大。並且在深度學習領域現今有使用 FP16 代替 FP32 的趨勢,因為較低精度計算對神經網絡其實並不太重要,尤其使用額外的精度並不會帶來任何好處,反而增加運算時間與佔用更多記憶體,但為什麼不能全用FP16,就能享有更快訓練時間與使用更低記憶體,而是要採用混合精度方案? 主要原因是使用FP16,容易發生溢出錯誤與捨入誤差。
實作
# 引用與定義
from torch.cuda.amp import autocast as autocast
scaler = torch.cuda.amp.GradScaler()
.... 省略 ....
# 需包住前向傳播和loss才會在過程使用自動混合精度
# 初略來說,進行訓練時會將矩陣乘法使用FP16進行運算,矩陣加法時使用FP32
with torch.cuda.amp.autocast():
y_pred = model(x_batch).squeeze()
loss = cross_entropy_loss(y_pred, y_batch)
# 對loss進行縮放,在進行反向傳播
# 防止FP16溢出錯誤,所以針對loss進行縮放
scaler.scale(loss).backward() # 替換原本loss.backward()
# scaler.step()首先把先前縮放調整為縮放比例,防止對學習率產生影響
# 如果數值有infs或者NaNs,那麼optimizer忽略這次迭代
scaler.step(optimizer)
# 更新下次迭代的scalar
scaler.update()